
Segmentation with Ambiguous/Partial Label
Introduction
Accurate segmentation of brain vessels is crucial for cerebrovascular disease diagnosis and treatment. However, existing methods face challenges in capturing small vessels and handling datasets that are partially or ambiguously annotated. In this project, we propose an adaptive semi-supervised approach to address these challenges. Our approach incorporates innovative techniques including progressive semi-supervised learning, adaptative training strategy, and boundary enhancement. Experimental results on 3DRA datasets demonstrate the superiority of our method in terms of mesh-based segmentation metrics. By leveraging the partially and ambiguously labeled data, which only annotates the main vessels, our method achieves impressive segmentation performance on mislabeled fine vessels, showcasing its potential for clinical applications.
Methods
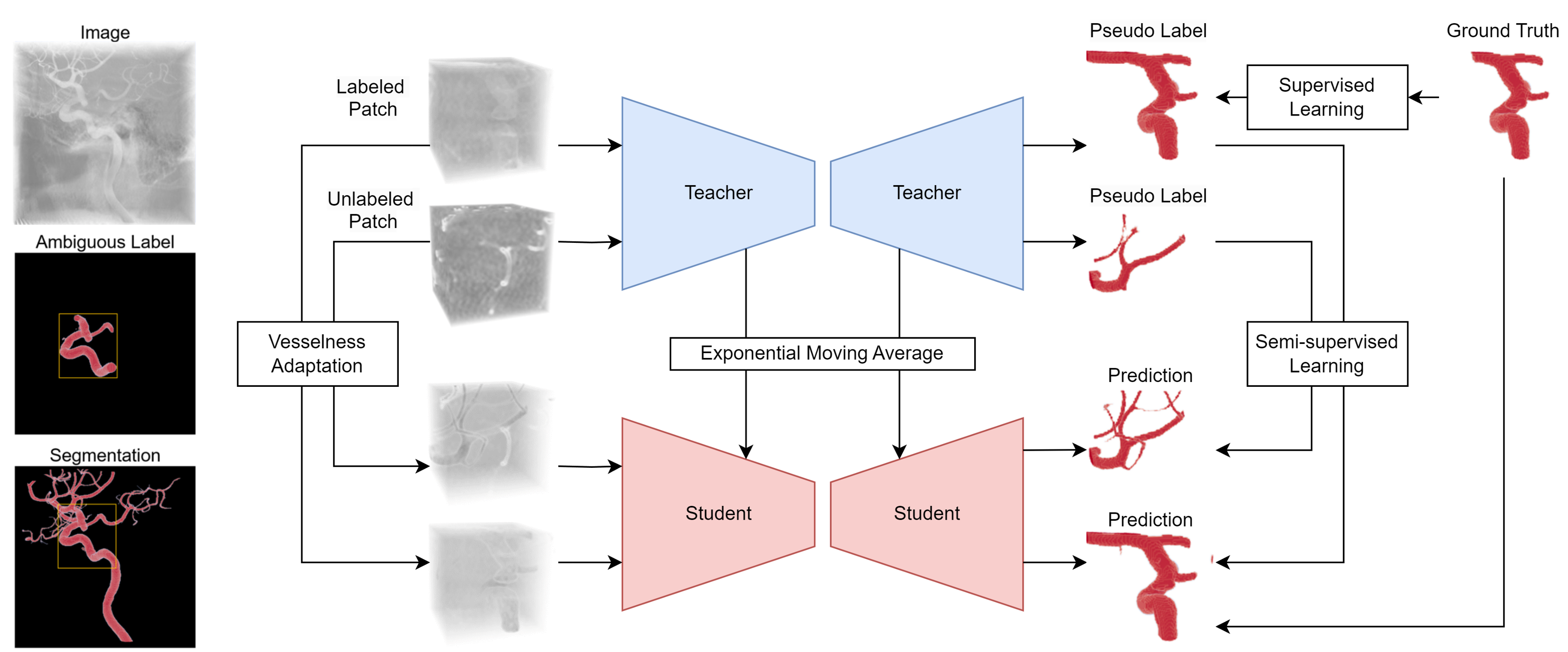 Schematic of the proposed adaptive semi-supervised model.
Schematic of the proposed adaptive semi-supervised model.
Results
We compared the proposed method with state-of-the-art approaches on four different data sources. Our method demonstrated superior performance in segmenting fine vessels without introducing excessive over-segmentation noise, especially in datasets with high levels of noise, such as ANSYS, ASD, and UPF. Notably, the nnUNet, being a highly fitted fully supervised approach, was greatly affected by ambiguous labels and could only segment major vessels. The Swin-UNet, utilizing the swin-transformer structure for feature extraction, outperformed convolution in nnUNet by extracting a larger number of vessel branches. VASeg, employing majority voting and thresholding techniques, achieved a better recovery of fine vessels. CPS, due to the utilization of semi-supervised cross pseudo-supervision, exhibited increased segmentation uncertainty and introduced excessive noise when handling datasets with higher noise levels. Because of our semi-supervised model’s emphasis on training robustness, the fully supervised loss is assigned a higher weight compared to the semi-supervised loss. As a result, the network becomes more conservative in its predictions. When dealing with datasets containing lesser noise, the model does not fully unleash its predictive capabilities. Instead, it tends to be more cautious and restrained in making predictions to ensure reliability. In contrast, our method showcased the ability to segment a significant number of fine vessels while maintaining robustness and avoiding the introduction of excessive noise.
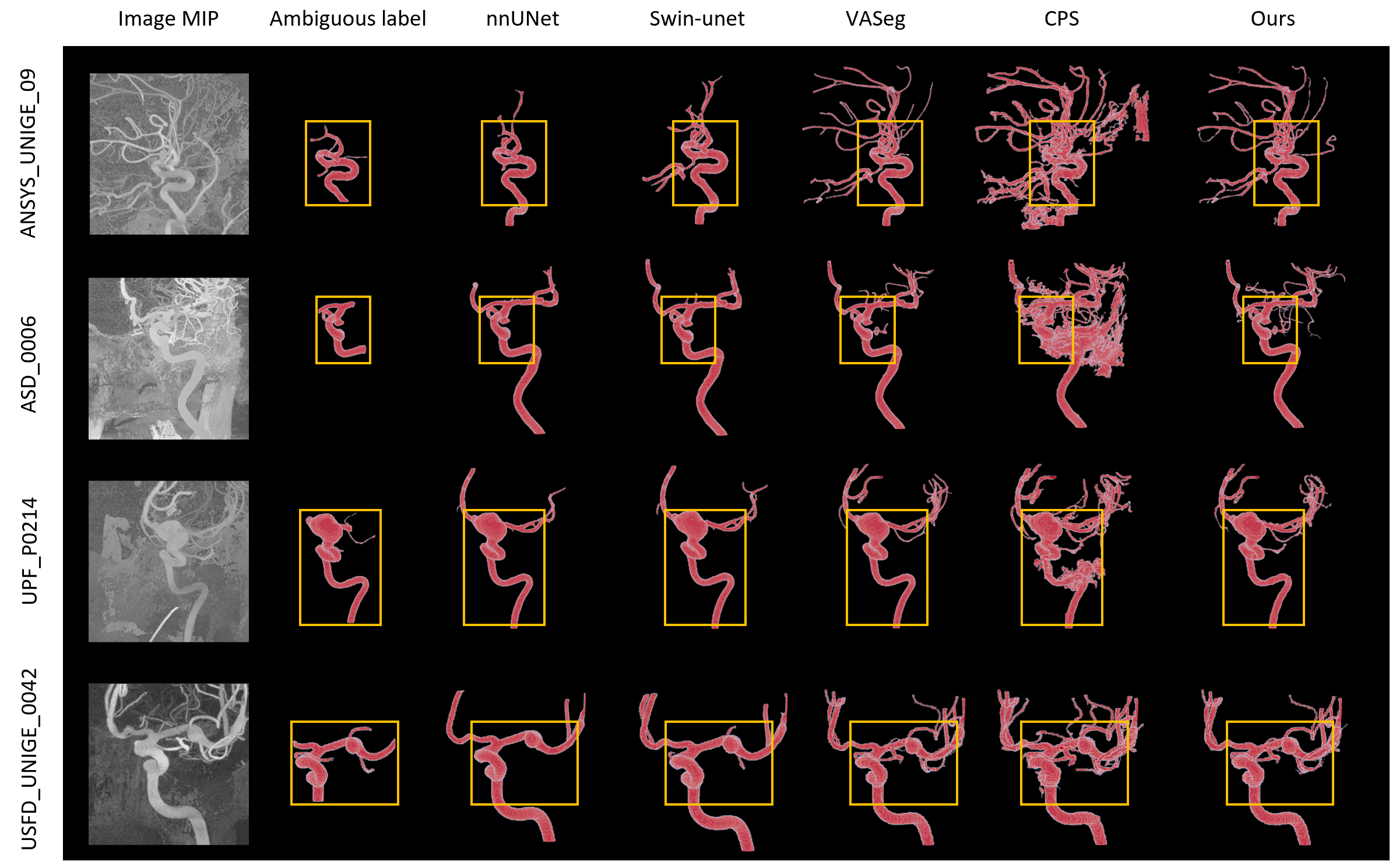 Comparison with State-of-the-Art Methods on four different data sources. The yellow box is the golden standard area where all quantitative evaluations are carried out.
Comparison with State-of-the-Art Methods on four different data sources. The yellow box is the golden standard area where all quantitative evaluations are carried out.